语音交互设计终极指南【UXRen译#272】

作者:Justin Baker | 翻译:邱文驰 审校:兔兔瑶-交互-北京
把闹钟调到早上7点15分
——好的,呼叫Selma Martin
不!把闹钟调到早上7点15分
——对不起,我帮不了你
“唉”,手动调闹钟
我们的声音是多样、复杂、多变的,即使在人与人之间,语音命令处理起来也会更难,更不用说计算机了。我们表达思想的方式,我们基于不同文化进行交流的方式,我们使用俚语并猜测含义的方式,所有的这些细节都会影响对语音的理解和解释。
那么设计师和工程师应该怎么面对这个挑战?我们怎样在人工智能和用户之间培养信任?这就是语音用户界面将会大展身手的地方。
语音用户界面(Voice User Interfaces (VUI) )是让人和设备之间的语音交互得以进行的主要或辅助的视觉、听觉和触觉界面。简单地说,一个语音用户界面可以是任何东西,可能是听到你的声音时灯闪了一下,或者是汽车的娱乐控制台等等。要记住的是,语音用户界面不一定是可见的——它可以只有听觉或触觉(比如,一个振动)。
语音用户界面是让人和设备之间的语音交互得以进行的主要或辅助的视觉、听觉和触觉界面。
虽然语音用户界面的范围很大,但都遵循着一套通用的有利于提高可用性的用户体验基础原则。根据这些基础原则,你可以从用户的角度对每天接触到的语音用户界面的交互进行分析,也可以从设计师的角度,用来建立更好的用户体验。接下来我们将探究这些基础原则。
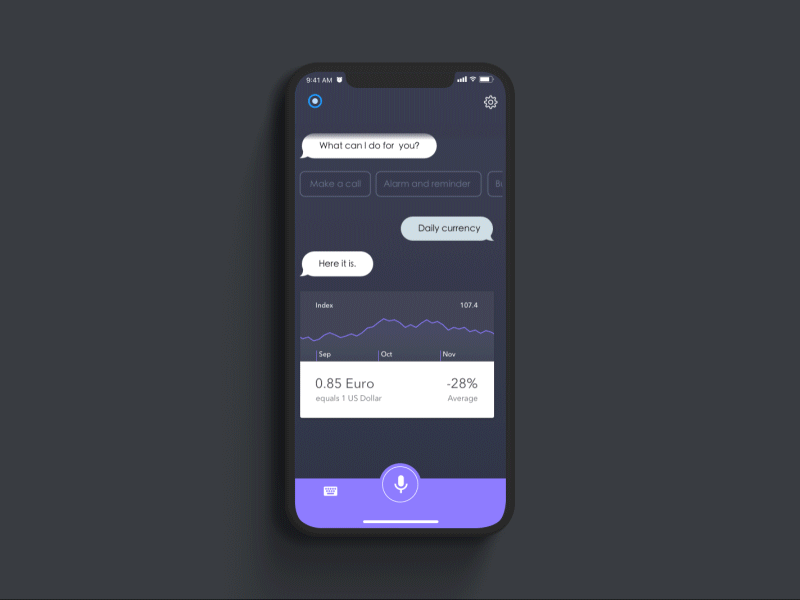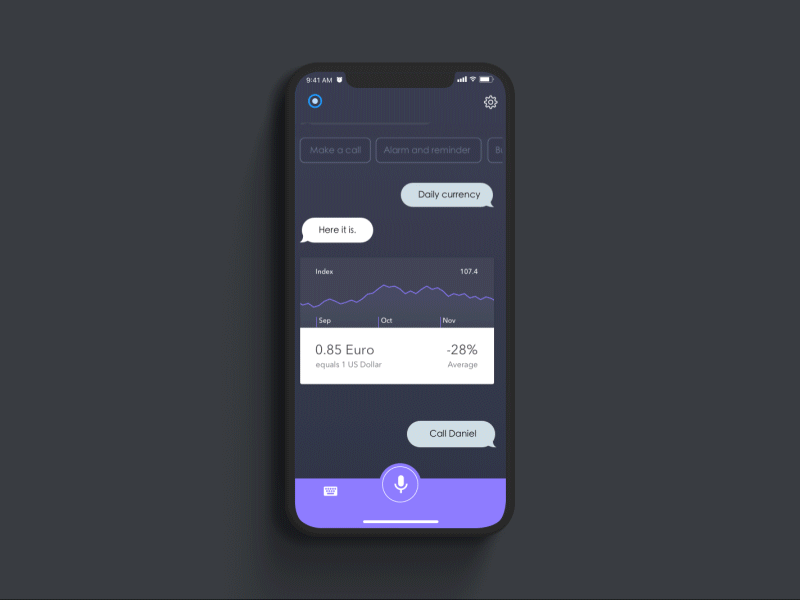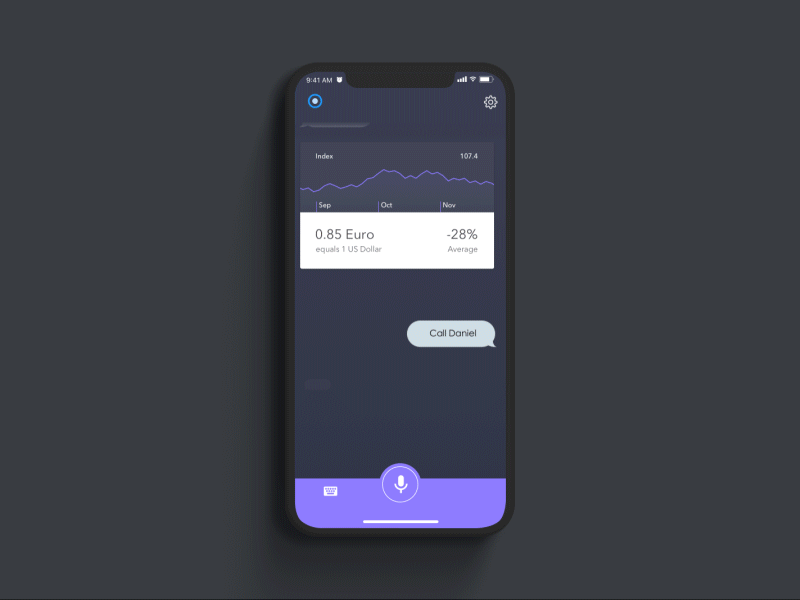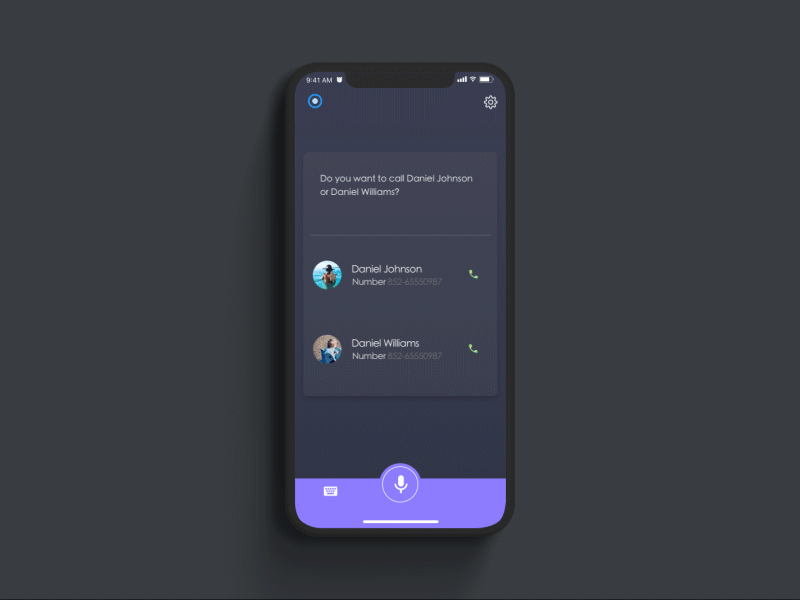
Dannniel
1、发现——限制、依赖、使用场景
我们的交互方式很大程度上受到技术、环境和社会的限制。包括传递信息的速度,把数据翻译成操作的准确性,跟数据和操作的接受方(不管是我们自己或者其他任何人)交流时使用的语言和术语。
因此在深入交互设计之前,我们必须先确定影响语音交互的背景环境。
1.1 设备类型限制
设备类型会影响语音交互的模式、语音输入的频率和范围。
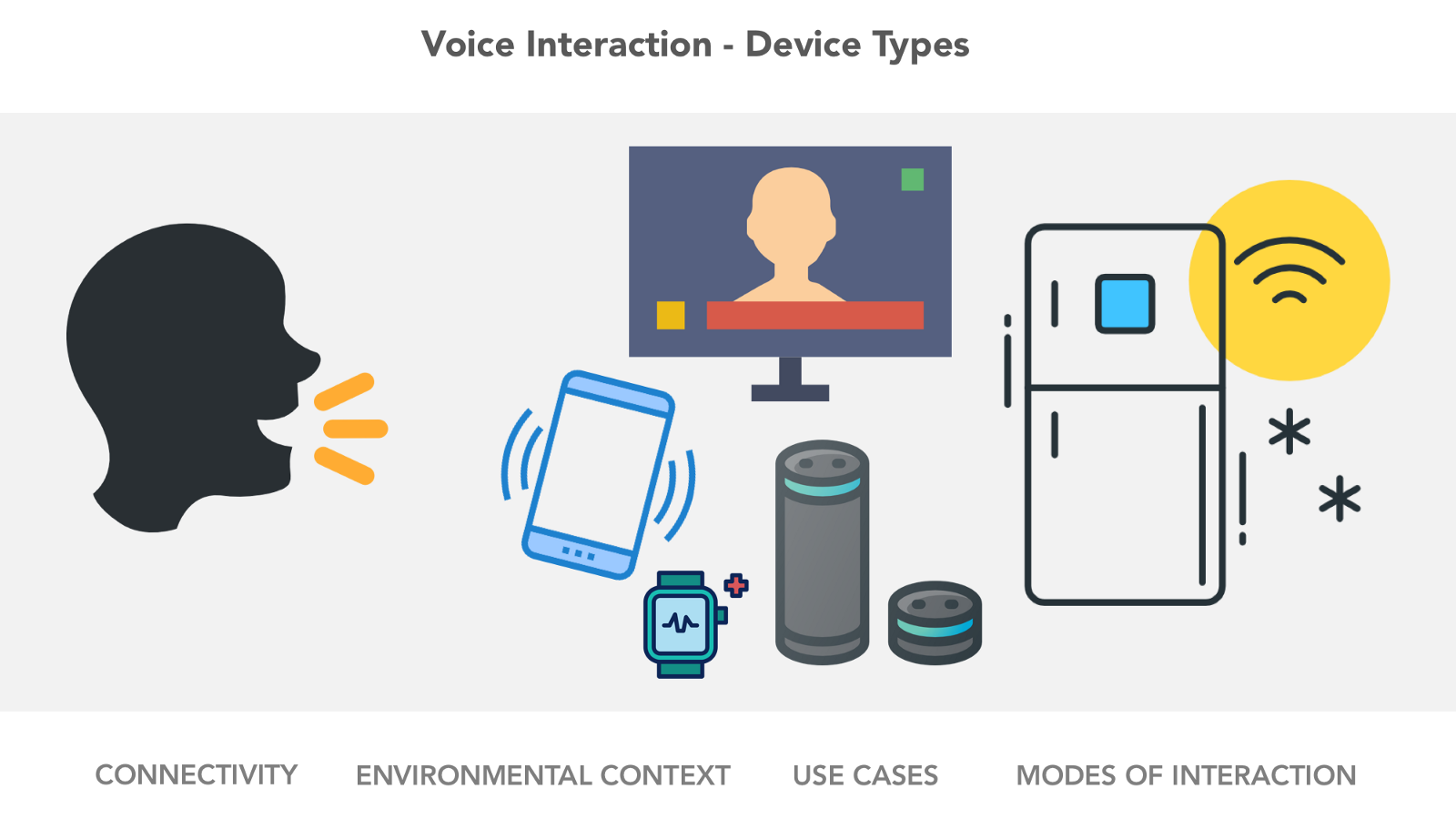
TV — Android Voice UI
电话
- 苹果手机、谷歌手机、三星手机
- 连接—蜂窝网络,wifi,配对设备
- 背景环境对语音交互有显著影响
- 用户习惯了使用语音交互
- 可以使用视觉、听觉和触觉反馈
- 在模型之间有相对标准化的交互方式
可穿戴设备
- 特定的使用场景,通常针对特殊的使用场景,比如手表、手环或者智能鞋子
- 连接—蜂窝网络,wifi,配对设备
- 用户可能习惯了使用语音交互,但不同的设备之间没有标准的交互
- 某些可穿戴设备可以使用视觉、听觉和触发反馈,但是有一些比较被动,没有明显的用户交互
- 通常依赖于连接设备来进行用户交互和数据消费
固定连接设备
- 台式电脑,带屏幕的电器,温度调节器,智能家居中心,语音系统,电视
- 连接—有线网络,wifi,配对设备
- 用户习惯了在相同的位置和基础的设置下使用这些设备
- 在相似的设备类型之间有相对标准化的语音交互方式(台式电脑、连接中心、智能温度调节器之间的对比)
不固定的计算设备(不是电话)
- 笔记本、平板、转发器、汽车娱乐信息系统
- 连接—无线网络,有线网络(不是公共的),wifi,配对设备
- 主要的输入模式通常不是语音
- 环境背景在语音交互上有显著的影响
- 通常在不同设备类型之间有非标准化的语音交互方式
1.2 创建使用场景模型
语音交互最主要的使用场景是什么?第二、第三个使用场景又是什么?设备是否有一个最主要的使用场景(比如健身记录仪)?或者是多个使用场景的混合(比如智能手机)?
创建使用场景模型的重要性在于它可以帮你确定用户跟设备交互的原因。他们主要的交互模式是什么?次要的交互模式呢?最好要具备的交互模式是什么,必不可少的又是什么?
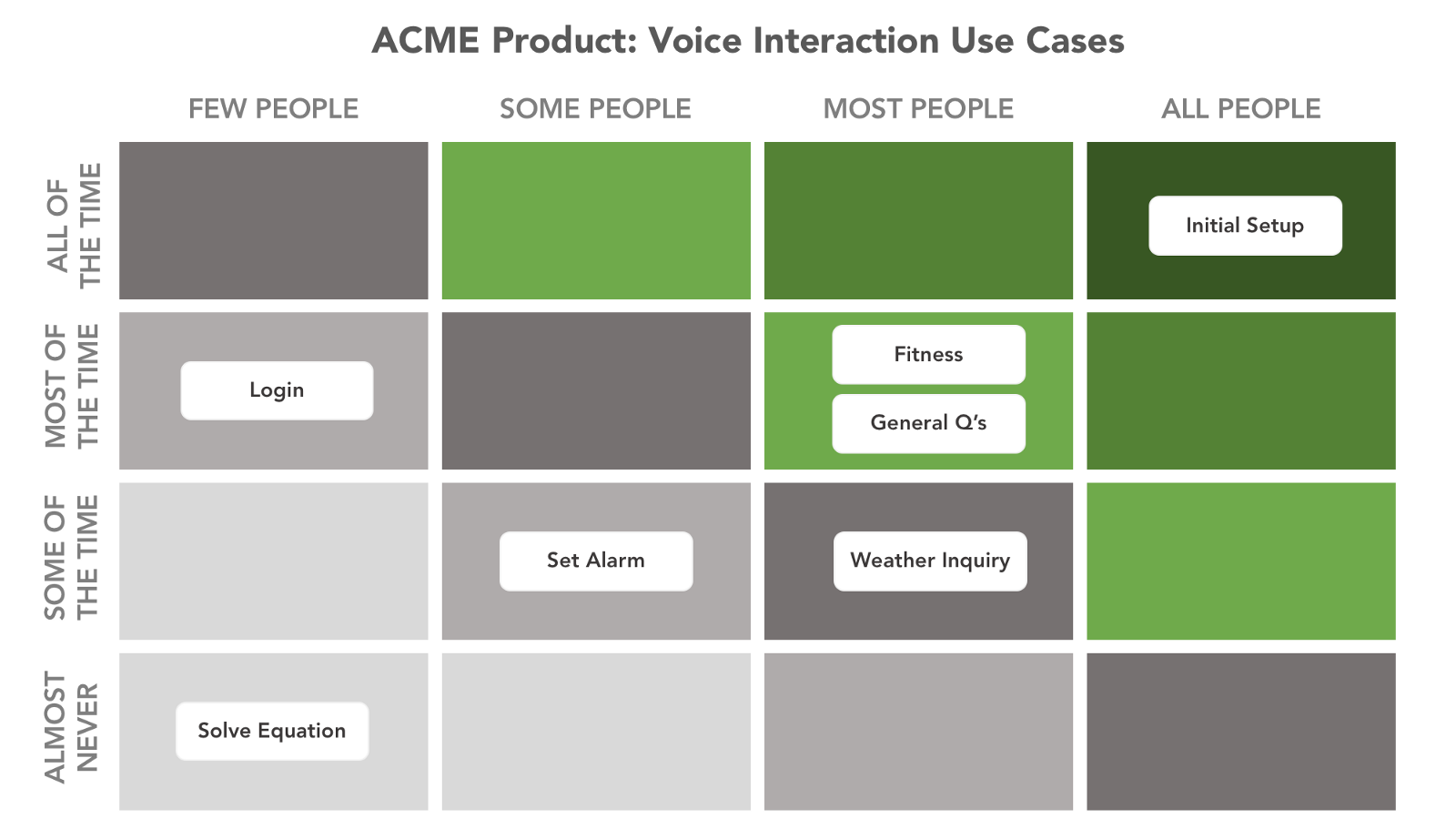
你可以为每个交互模式创建使用场景模型。具体应用到语音交互上,模型可以帮你理解用户当前或将要怎么使用语音和产品进行交互-包括他们会在哪里使用语音助手。
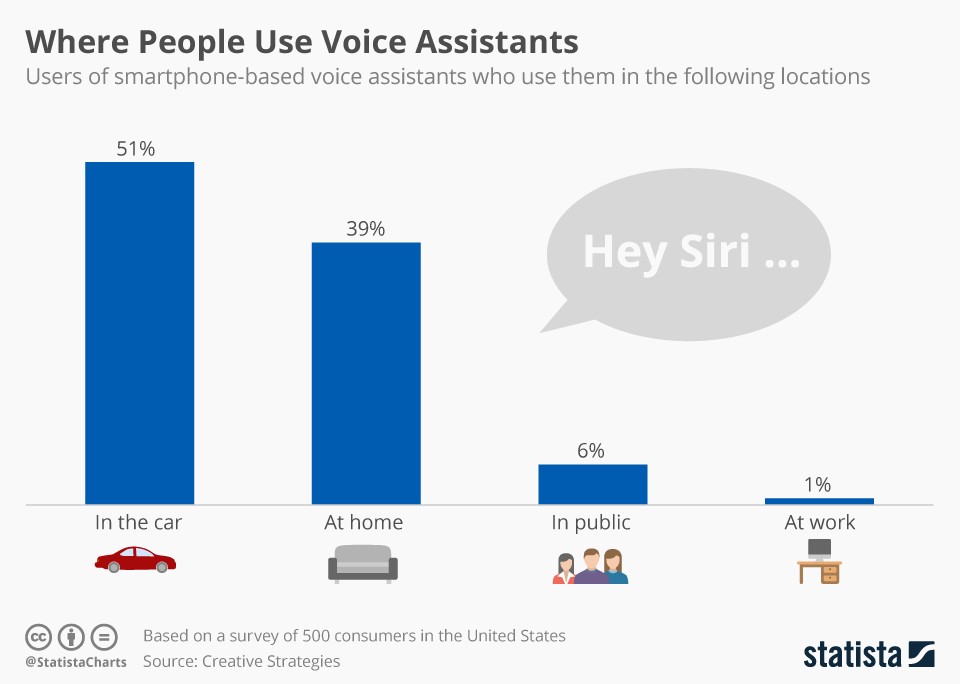
为交互模式排序
如果你正在通过用户研究去验证使用场景(使用惯用方法或者原始的定量/定性研究),那么很重要的一点是,你可以通过对不同角度的交互模式进行排序去证明你的分析。
如果有人告诉你,“我的天,如果可以和电视说话,让他切换频道的话就太酷了”。接着你需要继续深入分析,他们真的会去使用这个特性吗?他们知道会有限制吗?他们真的理解自己使用这个特性的倾向吗?
作为一个设计师,你必须比你的用户更加理解他们自己。
你必须考虑到他们使用特定的交互模式去获得备选内容的可能性。
比如,假设我们正在测试用户是否喜欢使用语音的命令和电视进行交互。在这种情况下,我们最好认为语音交互是多种可能的交互类型之一。
用户有多种可选的交互工具:遥控器,配对智能手机,游戏控制器或者已连接的物联网设备。因此语音没必要是默认的交互模式,只是多种模式中的一种。
所以问题就变成了:有多大的可能性用户会把语音交互作为主要依赖的交互方式?如果不是主要的,会是第二个吗?或者是第三个?这会限制你的假设和用户体验上的设想。
列举技术的限制
把我们的话翻译成对应的操作是一项特别困难的技术挑战。如果没有时间限制,通过连接和训练,一个调试好的计算机引擎可以方便地获取我们的对话并触发适当的操作。
不幸的是,我们并不是生活在无限连接的世界(比如无所不在的超高速互联网),我们也没有无限的时间。但我们想要语音交互跟传统的方式一样及时:比如视觉和触觉-即使语音引擎要求复杂的执行过程和预测模型。
这里是一些例子,表明我们的对话被识别时发生了什么:
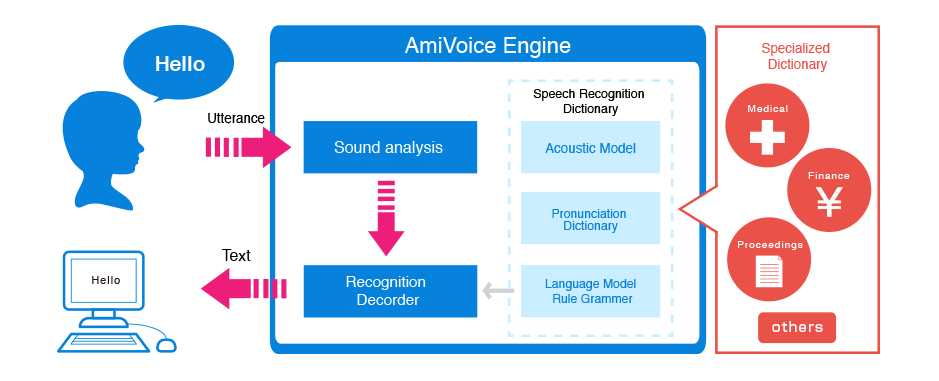
AMI Voice Engine
正如我们所见,有大量需要持续地通过词典、口音、多种音调等进行训练的模型。
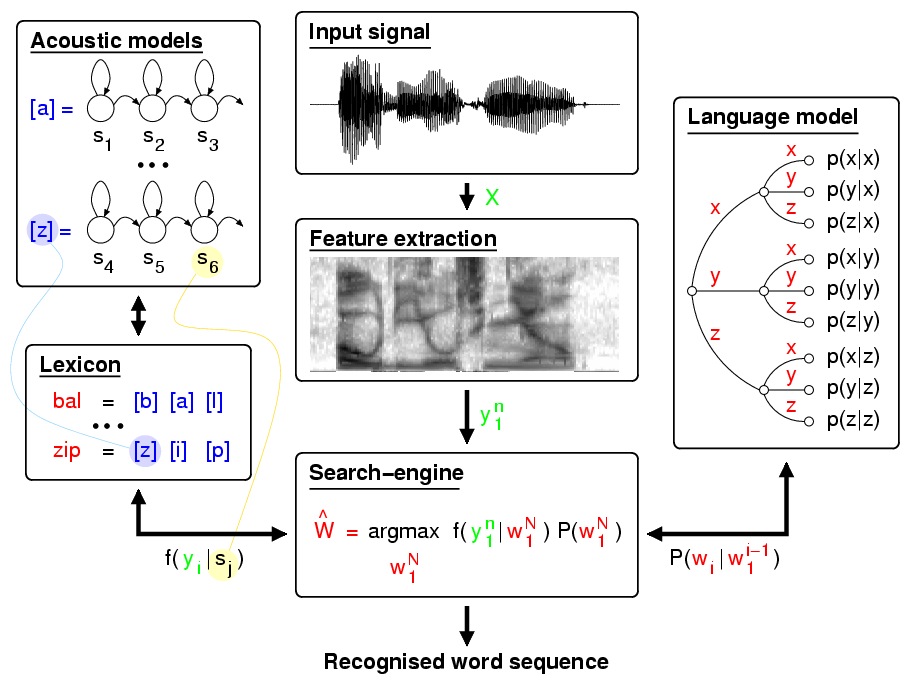
Automatic Speech Recognition
每个语音识别平台都有一系列特殊的技术限制。在设计语音交互的用户体验时,接受这些限制是十分必要的。
分析以下的类型:
- 连接水平
设备是否总能连接到互联网? - 执行速度
用户是否需要实时进行对话? - 执行的准确度
准确度和速度之间是怎么权衡? - 讲话模型
怎么我们当前的模型训练得好吗?是否能够准确地识别整个句子或者只是简短的单词? - 预设机制
如果对话不能识别时,技术备案是什么?用户可以使用另外的交互模式吗? - 错误的结果
被错误执行的命令会导致不可逆的操作吗?我们的语音识别是否有完善的机制去避免严重的错误? - 环境测试
语音引擎是否在多种环境背景下测试过?比如,如果我正在构建汽车娱乐信息系统,那么我会预期这比构建一个智能温度调节器受到更多的背景环境干扰。
非线性
另外,我们也要考虑到用户可以用非线性的方式和设备交互。比如,我想在网页上预订一张飞机票,我就会跟着网站的信息流一步步进行:选择目的地、选择日期、选择票的数量、查看选项等等…
但是,语音用户界面有更大的挑战。用户可以说“我们想要飞去旧金山的商务舱”,语音用户界面就要从用户身上提取所有相关的信息,才可以使用现有的航班预订接口。逻辑顺序可能是有偏差的,所以语音用户界面有责任去提取用户的相关信息(也可以通过语音或者视觉来补充)。
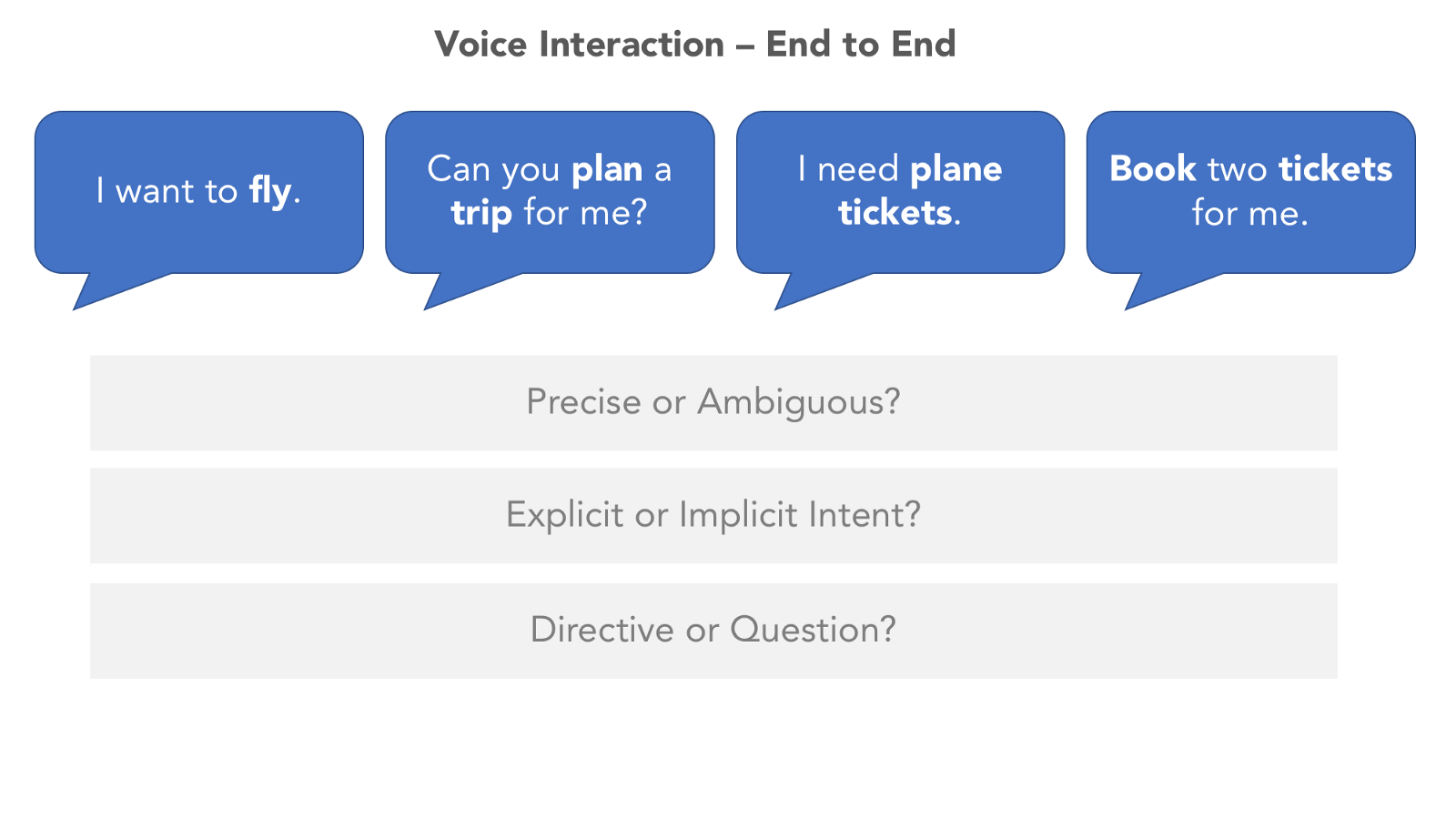
2、语音输入的用户体验
探索了语音用户界面的限制、依赖和使用场景之后,我们可以开始慢慢深入到真实的语音体验中。首先,我们将探究设备是怎么知道什么时候要听我们说话的。
作为一些补充背景说明,下面这个图表描述了一个基本的语音体验流程:
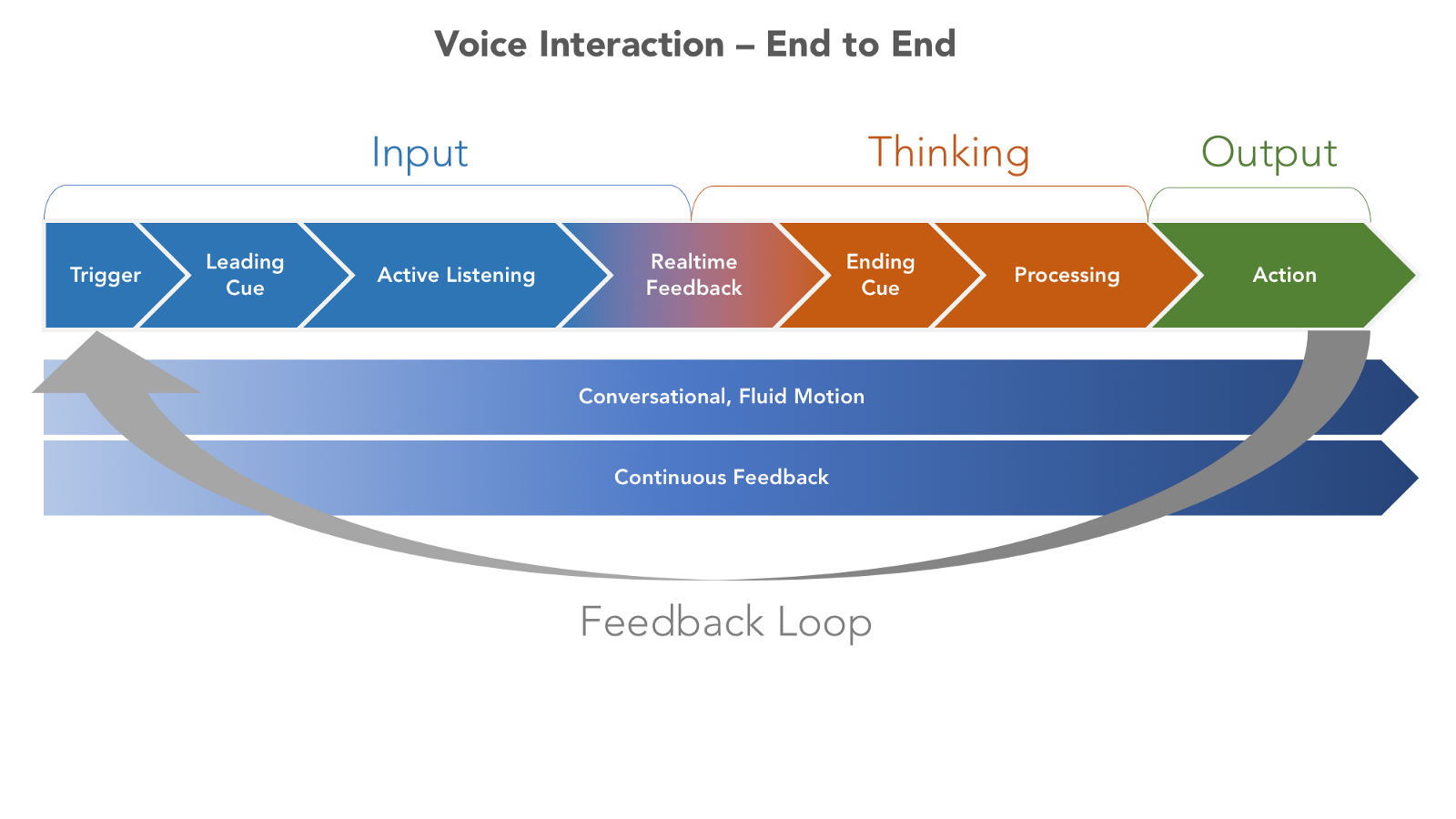
就像这样子…
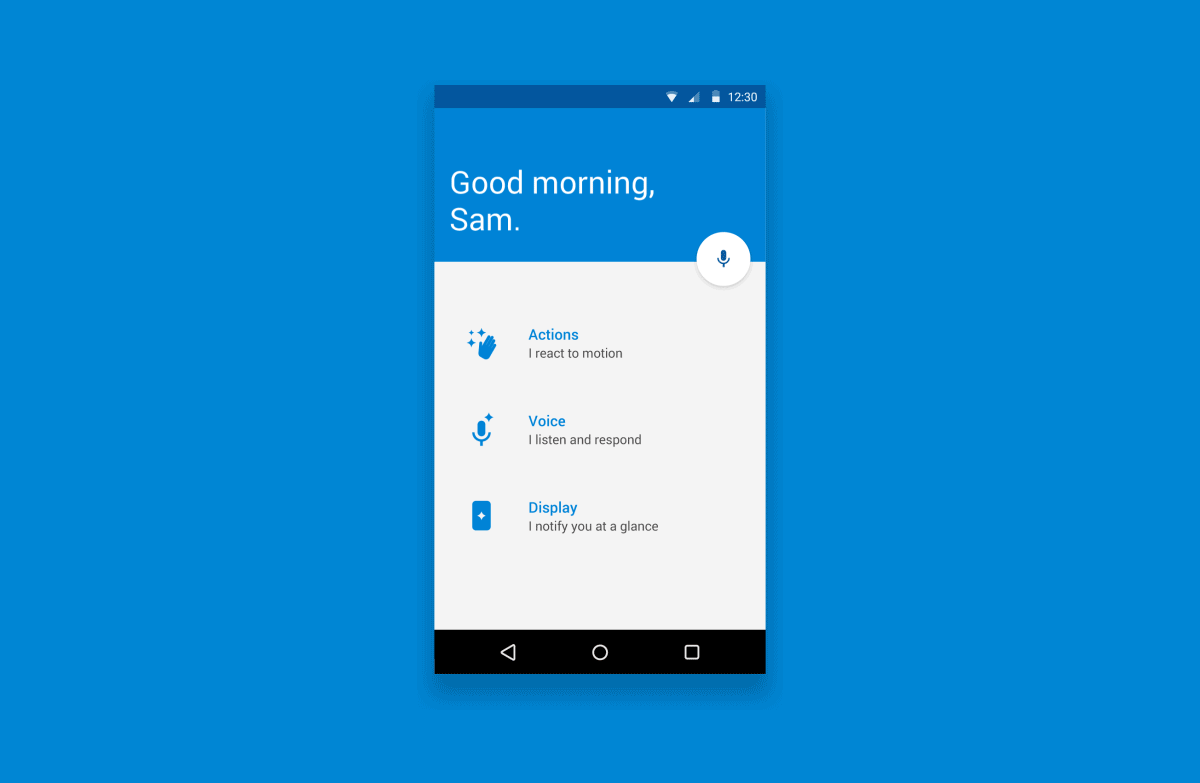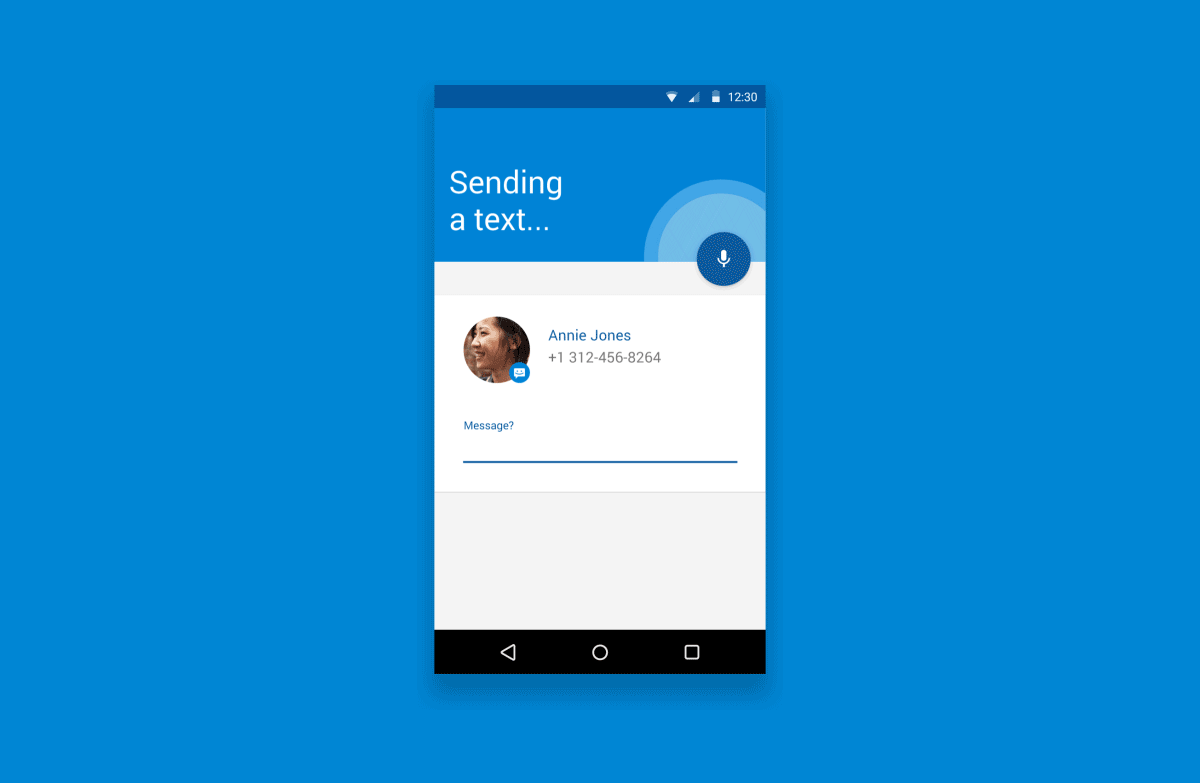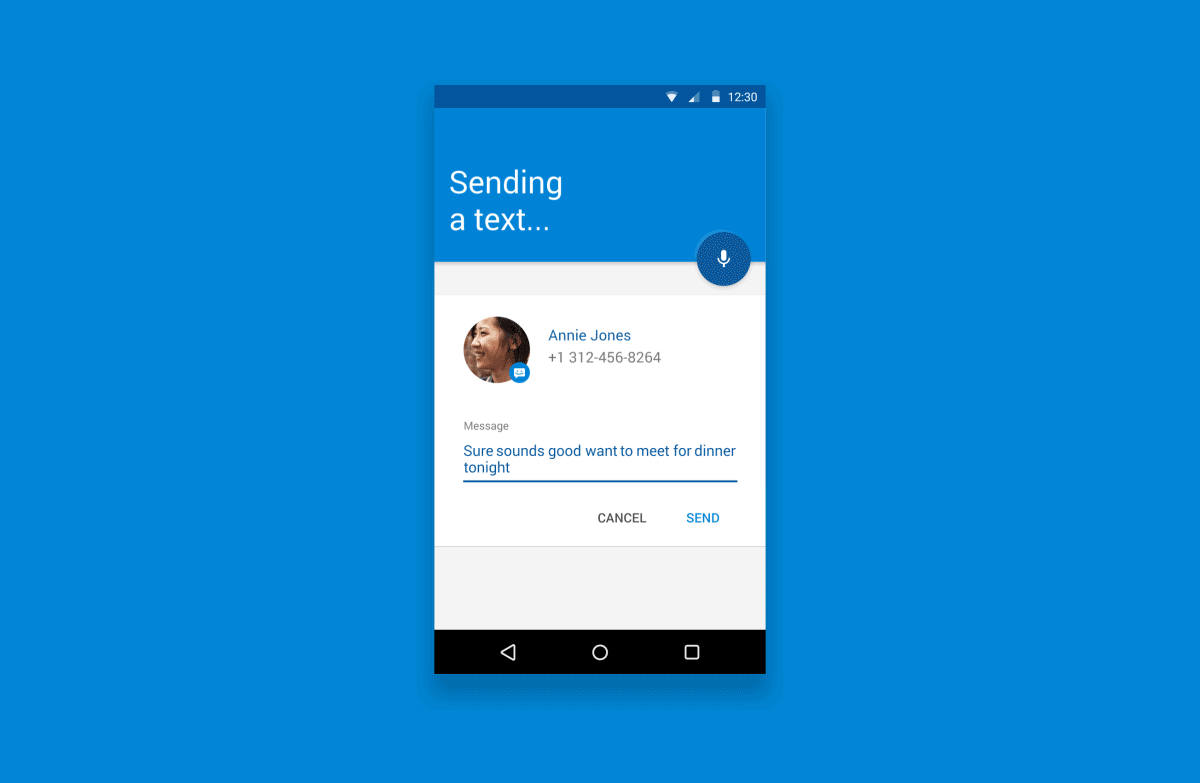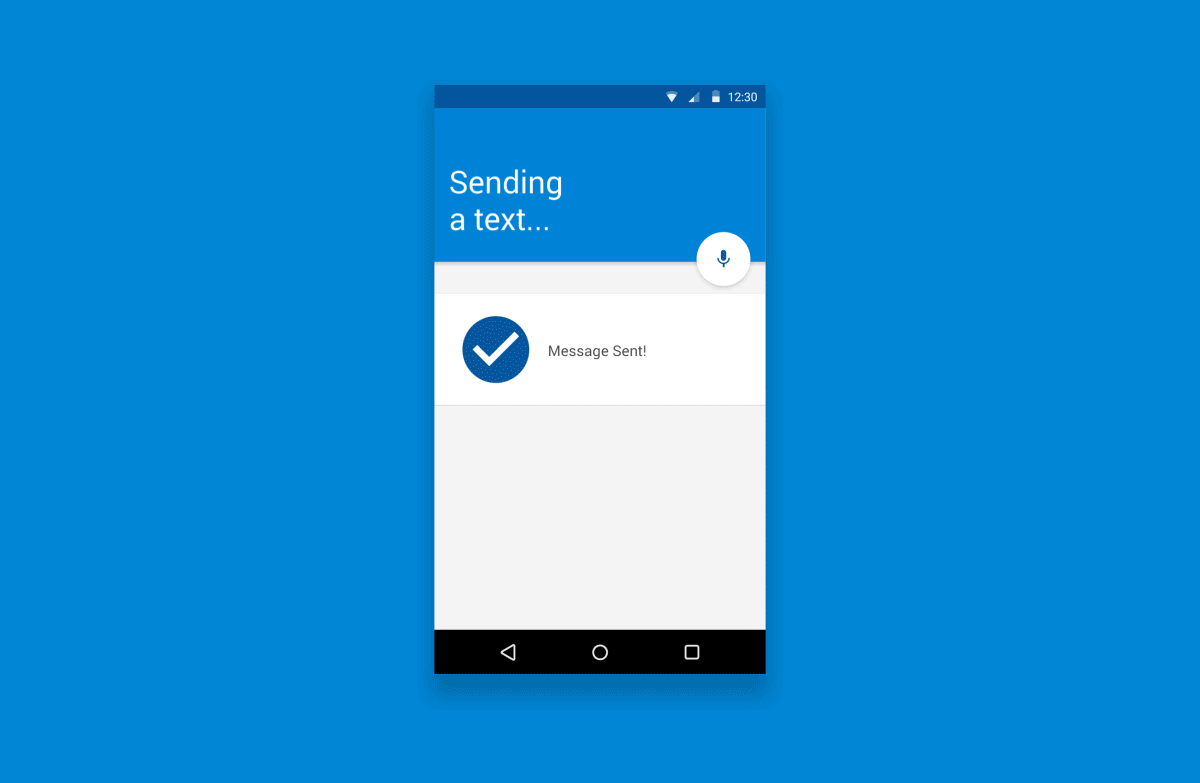
2.1 触发
有四种触发语音输入的类型:
- 语音触发
用户会说出一个词来激发设备,然后设备就开始处理语音(“Ok Google”) - 触觉触发
按一个按钮(物理或者虚拟)或者切换一个控制器(比如,一个麦克风图标) - 运动触发
在传感器前面挥手 - 设备自己触发
某个事件或者预先配置好的设置会触发设备(一个汽车事故或者一个需要你确认的任务提醒)
作为设计师,你必须理解哪种触发和使用场景相关,然后将这些触发按有关到无关进行排序。
2.2 开始提示
一般来说,当一个设备被激活时,会有一个听觉、视觉或者触觉的提示。

The Wirecutter

提示应该遵从以下可用性原则:
- 即时
在合适的触发之后,提示应该尽快出现,即使这个提示会打断当前的操作(只要打断这种操作不是破坏性的)。 - 简短
提示应该是瞬间发生的,特别是在经常使用的设备上。比如,两下明确的响声比“你好,希望我现在为你做什么呢?”更有效。开始提示越长,用户说的话越有可能跟设备的提示发生冲突。这个原则也适用于视觉提示,屏幕应该立即切换到倾听的状态。 - 起点清晰
用户应该准确地知道他们说的话什么时候开始被记录。 - 一致
提示应该保持一致,声音或视觉反馈的不同会让用户产生困惑。 - 区分
提示应该跟设备正常的声音和视觉区分开-而且不能在其他任何背景下使用或者重复 - 补充提示
在可能的情况下,使用多种交互媒介去展示提示(比如,两下响声,一盏灯发生变换和一个屏幕上的对话框)。 - 初始提示
对于第一次使用的用户,或者当用户似乎陷入困境时,你可以展示一个初始提示或者建议去,帮助用户进行语音交流。
2.3 反馈的用户体验
反馈对成功的语音用户界面是非常重要的。它能够让用户得到一致且即时的确认,明确他们说的话已经被设备获取并执行。反馈也让用户能够对操作进行矫正或确认。
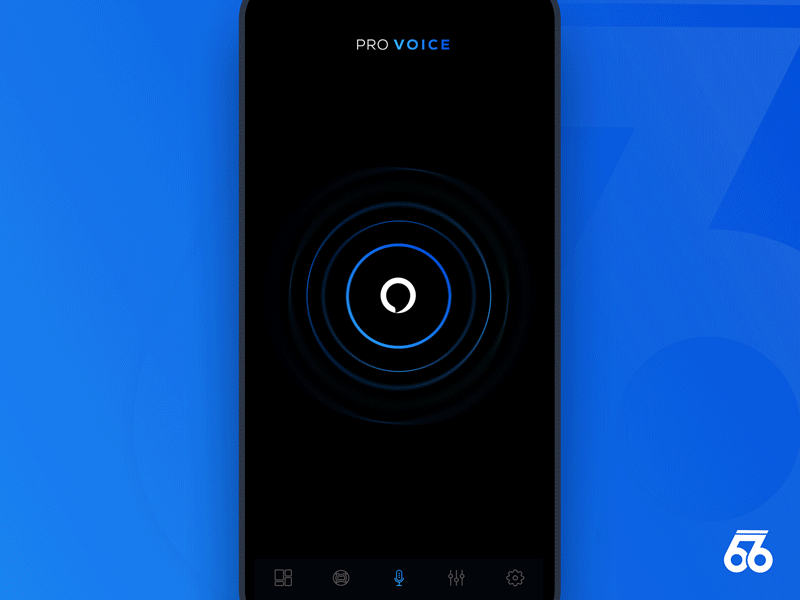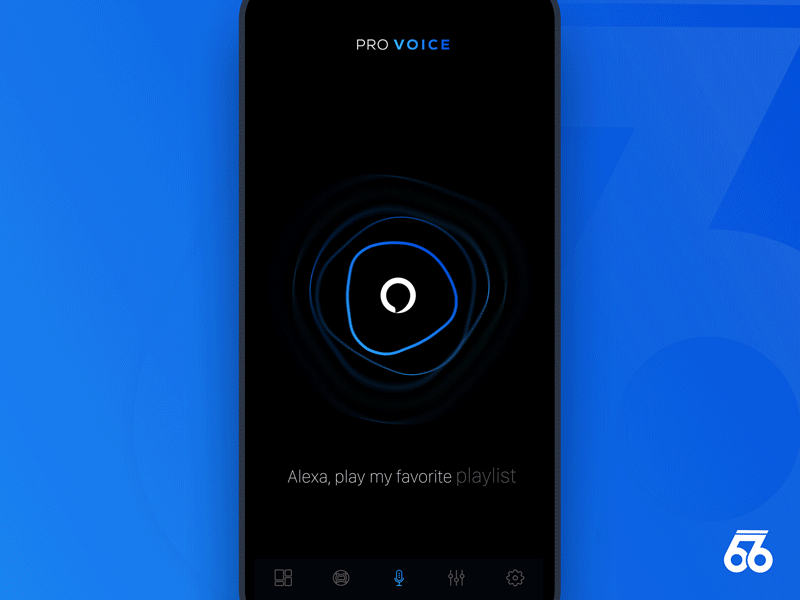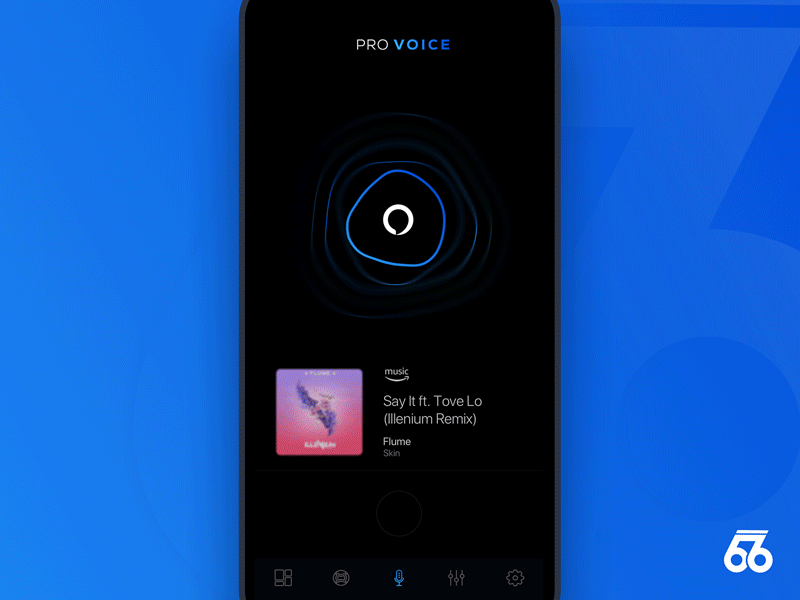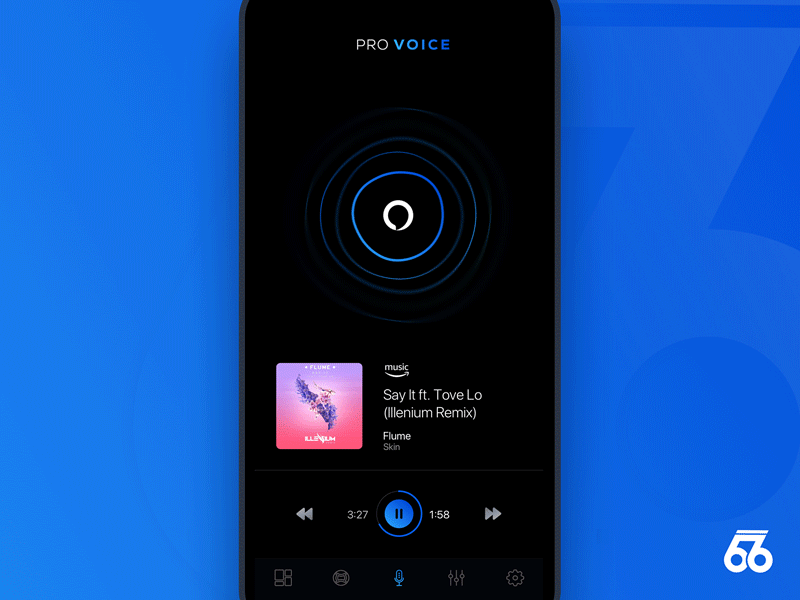
Samborek
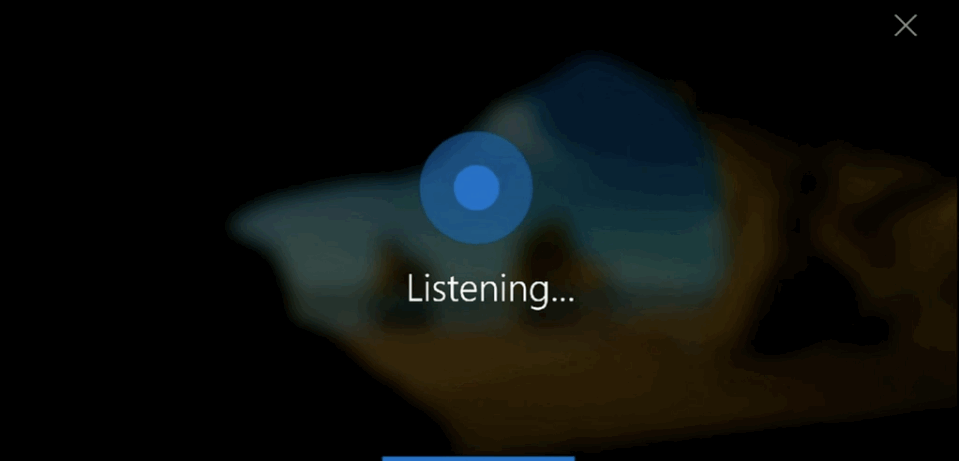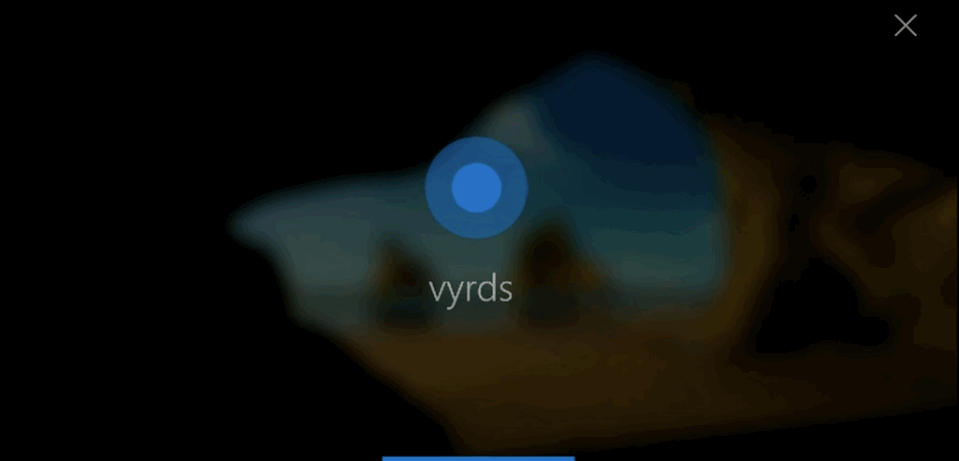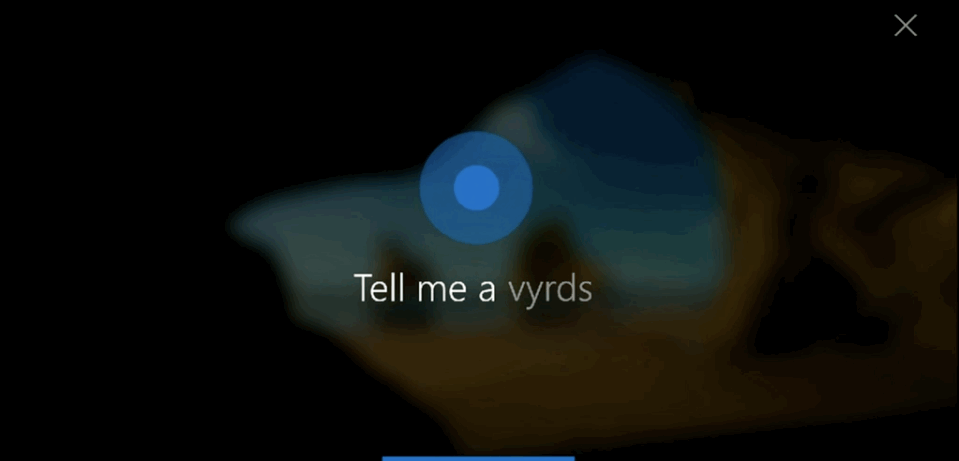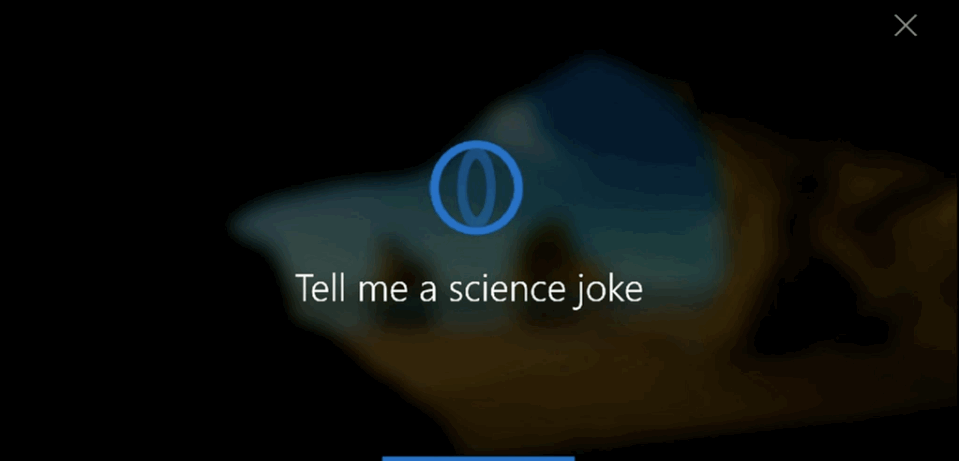
Cortana
这里是一些可以提供有效的语音用户界面反馈的用户体验原则:
- 实时响应的视觉
视觉反馈是原生语音设备中最常见的(比如电话),通过声音的多种维度(音调、音色、音量和持续时间)来创造即时的认知反馈——这些维度可以相应地实时改变颜色和模式。 - 声音回放
简单的回放能用来确认对话解释的正确与否。 - 实时文本
用户在说话时,可以实时地显示文本的反馈。 - 输出文本
用户说完之后被转换和修改的文本反馈。把这个当做在声音被确认或者转化成操作之前的第一层修正处理。 - 无屏幕的视觉提示(灯,灯光模式)
上面提到的实时响应的视觉反馈不只是局限在电子屏幕上,这些响应模式也可以用简单的led灯或灯光模式来展示。
2.4 结束提示
这个提示表示设备已经停止倾听用户的声音而且要开始执行命令了。“开始提示”中很多同样的原则也可以应用于结束提示(即时、简要、清晰、一致和区分),但是也有一些额外的原则:
- 足够的时间
确保有足够的时间让用户完成他们的命令。 - 适当的时间
时间的分配应该适应使用场景和期待回应的内容。比如,如果用户被问到“是”或“否”的问题,结束提示应该在一个音节之后有适当的停顿。 - 适当的停顿
最后一个声音被记录后是否有一个适当的停顿?这个很难去计算,但也可以取决于交互的使用场景。
3、对话的体验
简单的命令比如“打开我的闹钟”不需要长的对话,但是一些更复杂的命令则需要较长的对话。跟传统的人与人的交互不同的是,人与人工智能的交互需要额外的确认、重复和纠正。
一般来说,更复杂的命令或渐进式的对话需要多层语音/选项验证来确保准确性。复杂的事件更是如此,用户经常不知道要问什么或者不知道怎么去问,所以去解读信息并允许用户提供额外的背景,就变成了语音用户界面的任务。
- 确定
当人工智能理解了用户说的话时,应该回复一个确定的信息,也可以同时确认对话。比如,不要说“好的”,应该说“好的,我会把灯关掉”-或者说“确定要我把灯关掉?” - 纠正
当人工智能不能解读用户的意图时,应该回复一个用于纠正的选项,允许用户选择另外一个选项或者重新开始对话。 - 同理心
当人工智能不能满足用户的要求时,应该为不能理解用户说的话而负责,并提供一些相关的操作给用户。这对人和人工智能之间建立更加个性化的关系是很重要的。
4、人性化的体验

Olly


在语音交互上提供跟人类似的特点可以在人和设备之间建立起某种联系。这种人性化可以通过多种方式来体现:灯光的模式、弹跳的形状,抽象的球体模型,计算机生成的语音和声音。
这种联系在用户和机器之间培养了更加亲密的纽带,也可以在有类似操作平台的产品之间拓展(比如谷歌助手、亚马逊的Alexa和苹果的Siri)
- 个性化
给交互带来一个额外的维度,允许虚拟的人格跟用户之间产生关联和同理心。可它有助于减轻错误处理的语音带来的负面影响。 - 积极性
积极性会鼓励用户使用更加肯定的语气再次进行交互。 - 自信和信任
鼓励额外的互动和复杂的对话,因为这会使用户对结果更有信心,结果将是积极的、更有价值的。
5、端对端动效用户体验
语音交互应该是动态的。我们和其他人交流时,一般会使用大量的面部表情、音调的变化、身体语言和动作。在数字化的环境中捕捉这种动态交互是很有挑战的。
可能的情况下,完整的语音交互体验应该像一个有意义的互动。当然,更多的是像“关灯”一样瞬间的交互,这就没必要具备完整的关联。但是,像让数字助理煮饭这样复杂的交互,就确实需要长时间的交流。

Aurélien Salomon
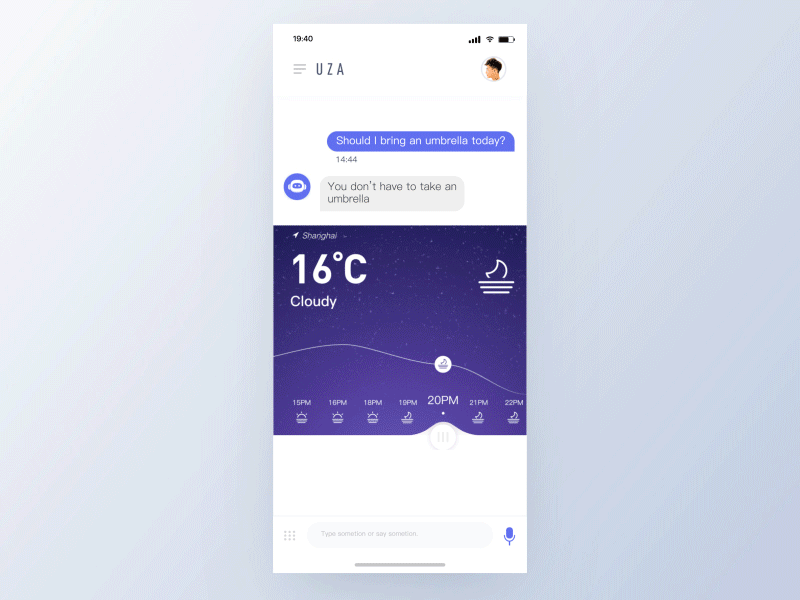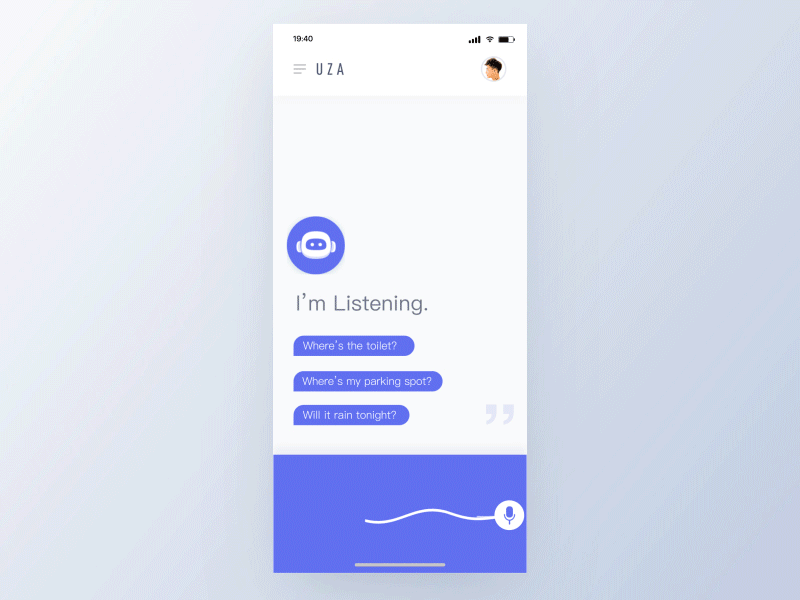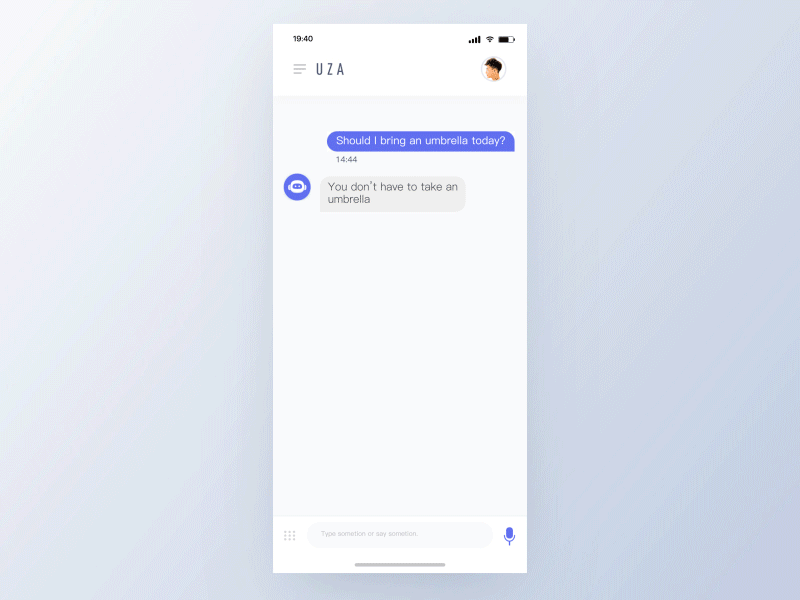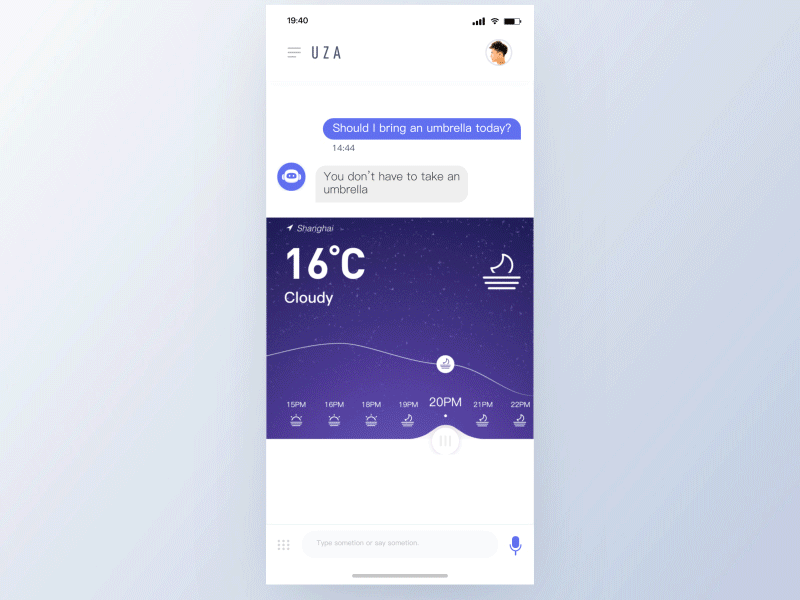
TinoFan
一个有效的语音动效体验会从以下原则中受益:
- 短暂
不同状态之间的无缝切换。用户应该感觉不到等待,而是认为助手正在为他们工作。 - 鲜明
鲜明的颜色能体现愉快和未来感,它为交互增加了未来主义优雅元素——可以激发再次交互。 - 响应
响应用户的输入和手势。给出关于正在处理哪些单词的提示,允许用户查看他们的对话/意图是否被准确地解析。
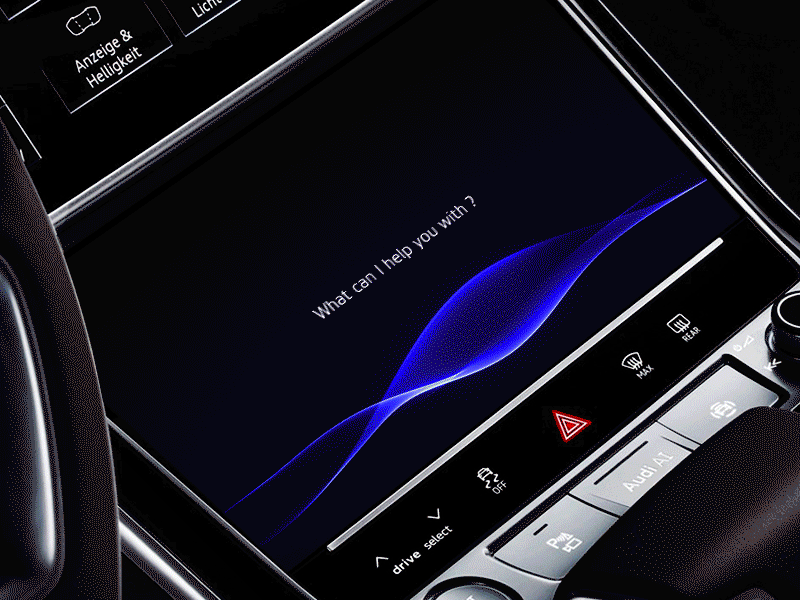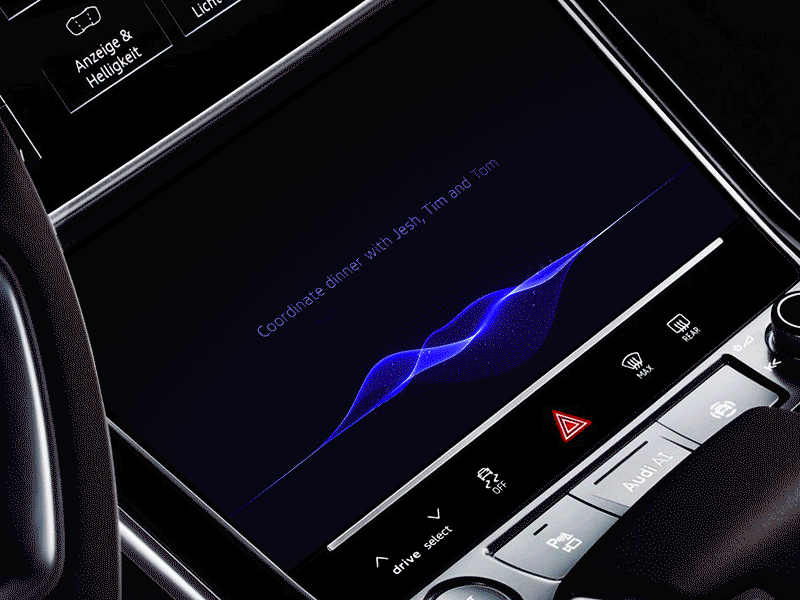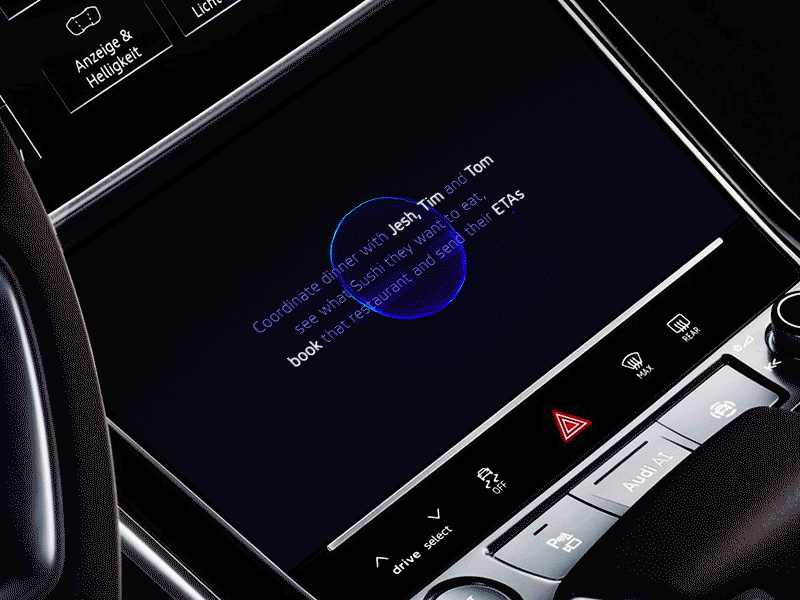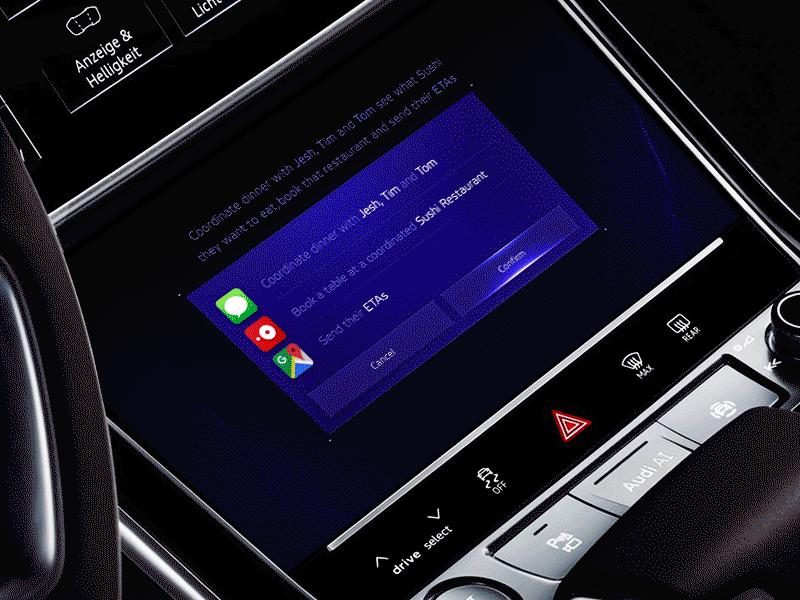
Natural AI inside AGI automotive dashboard by Gleb Kuznetsov✈
6、结论
语音用户界面是一个非常复杂、多样、经常有多种内容混合的交互界面。事实上,语音用户界面还没有一个真正全面的定义。但要记住,随着世界的数字化,可能实际上我们跟设备对话的时间比跟人之间对话的时间还多。语音用户界面会变成我们主要的交互方式吗?让我们拭目以待。
更多译文:
新用户“引导设计”的全流程教学
解密快进快出的“浅交互设计”
为什么好的服务设计不能保证顾客的忠诚度?
如何设计有效和负责任的奖励机制
深度访谈的提纲设计与操作指南
全部270+篇译文>>
申请加入UXRen翻译组>>

翻译:邱文驰 审校:兔兔瑶-交互-北京
作者:Justin Baker
原文标题:《Voice User Interfaces (VUI) — The Ultimate Designer’s Guide—The fundamentals that empower us to converse with our devices》
原文链接:https://medium.muz.li/voice-user-interfaces-vui-the-ultimate-designers-guide-8756cb2578a1
发布日期:Nov 25, 2018
版权声明:
- 本文版权归:UXRen翻译组 所有;
- 微信公众号转载说明:
1)由于近期微信审理严格,若是该文章未在UXRen公众号上首发,请不要转载;
2)公众号转载时,请在文章底部贴上UXRen公众号二维码。 - 网站转载说明:
1)文章标题必须保留“UXRen译”字样;
2)转载文中必须保留:“UXRen翻译组”、“作者”、“译者”及“审校者”信息;
3)转载文末必须保留本译文网页链接地址; - 如未遵照上述规则转载,视为侵权,UXRen社区保留随时追责的权利。







