A/B测试中12个常见误区【UXRen译#290】
原作者:Peep Laja | 翻译: 晓臣同学 审校:王猫猫
UXRen
A/B测试很有趣。市面上已经有许多方便易用的工具,我们都可以(也应该)做到。然而A/B测试不仅仅是进行测试那么简单。以下12个常见的A/B测试误区,浪费了许多企业的时间和金钱。
以下是我在工作中屡见不鲜的误区。你有犯过这些错误吗?读一读就知道了。
UXRen
1. 过早停止A/B 测试
统计显著性是在样本量足够大的前提下,A版是否优于B版的判断标准。50%的统计显著性即指结果随机。如果你对显著性的要求只有50%,那就该转行了。统计置信度即便达到75%也不够好。
经验丰富的测试人员都有许多这样的经验,即使80%置信度下的“胜出”的版本,在投放市场后也以失败告终。
90%的置信度怎么样?应该可以了吧!
不,还不够好。你是在做科学实验。是的,你希望证实实验假设,希望置信度达到90%的版本胜出,但比“宣布胜出者”更重要的,是找到真相。

作为“优化者”,你的职责是找出真相。因此必须把自我放在一边。你更倾向认可自己的假设或设计方案,这是人之常情;当你最优的假设没有出现显著性差异时,你会很受打击。对此,我感同身受。真相高于一切,否则一切都失去意义。
即使经常进行A/B测试的公司也常见此种情况:一年里一个接一个地运行测试,在测试后将胜出者推出。但一年后再看,转化率竟然与最初版本差不多!这种打脸的情况总是发生。
为什么?要么是测试结束得太早,要么是样本量太小,或者兼而有之。我曾在一篇博文里详细作了解释,题目是《何时停止A/B测试》,但简而言之,在宣布测试完成之前,你需要满足3个指标:
- 有足够的样本量:实验有足够的人参与,以便有足够的数据来获得科学的结论。需要使用A/B测试样本量计算器预先计算所需样本量。
- 测试需要运行多个销售周期,2到4周左右。如果你只做了几天就停止测试(即使达到了所需的样本量),也只是取了便利样本,而不是有代表性的样本。
- 显著性达到95%(P≤ 0.05)或以上。注意:记住P值并不能告诉我们方案B比方案A好,这一点非常重要。(译者注:P值指的是对比事物间的差别是由机遇所致的可能性大小。P值越小,越有理由认为对比事物间存在差异。例如,P<0.05,就是说结果显示的差别是由随机因素所致的可能性不足5%,或者说,别人在同样的条件下重复同样的研究,得出相反结论的可能性不足5%。P>0.05称“不显著”;P≤ 0.05称“显著”,P≤ 0.01称“非常显著”。)
这里有一个经典案例来说明我的观点。测试两天后的数据结果如下:

图表中的文字翻译如下:
| 版本 | 转化率范围 | 改善率 | 优于原版本比率 | 转化/访客量 |
| 对照版本 | ||||
| 新版本1 | ||||
| 平均值 |
我构建的版本相比对照版本损失惨重,超过89%(误差范围没有重叠)。一些测试工具可能已经判断其统计显著性达100%。当时我所使用的软件给出的结论是,我的版本完全不可能优于对照组。我的客户已经准备好宣布停用这个方案。
然而,由于当时样本量太小(每个组只有100次以上的访问量),我坚持继续收集数据,这是10天后的情况:

图表中的文字翻译如下:
| 版本 | 转化率范围 | 改善率 | 优于原版本比率 | 转化/访客量 | 行动 |
| 对照版本 | |||||
| 新版本1 | |||||
| 平均值 |
如你所见,曾经完全没可能击败对照版本的新版本现在以95%的显著性获胜。
有些A/B测试工具会让你过早结束,这得当心,一定要反复检查数据。最糟糕的情况就是,你采信了实际并不准确的数据,导致不仅损失了大量金钱,很可能几个月的努力也都付之东流。
需要多大的样本量?
小样本基础上得出的结论不靠谱。好的样本区间是每个测试版本至少有350-400次转化数据(在某些情况下,比如当对照版本和优化方案之间的差异很大时,转化数据要求可以稍低一些)。但是,不存在放之四海皆准的标准样本量。不要被数字束缚——这是科学,而不是魔法。
你一定要提前用样本量计算器计算出实际需要的样本量,以确保实验的准确性。
如果每个变量版本都有超过350转化数据的样本量,而置信度依旧未达到95%以上呢?
如果测试达到所需样本量,则意味着不同版本之间没有显著差异。检查测试中各分指标的结果,看看是否在其中某一个或几个中实现了显著性(优秀的洞察总是出现在细节中,但也要确保每个分指标都有足够的样本量)。无论如何,你都需要优化假设,运行新的测试。
UXRen
2. 测试未以整周为单位运行
假设你有一个高流量的网站,A/B测试开始后3天就有98%的置信度,并且每个版本都有250次转换数据。那这个测试算完成了吗?还没有。
我们需要排除周期性因素,以整周为周期进行测试。如果你星期一开始进行测试,那么也需要在下星期一结束。为什么?因为在一周里转化率会变化会非常大。
所以如果你的测试周期没覆盖一个完整周,结果又会出现偏差。按周输出你网站的每日转换率报告,看看每天的转化率有多大的波动。下面是一个例子:
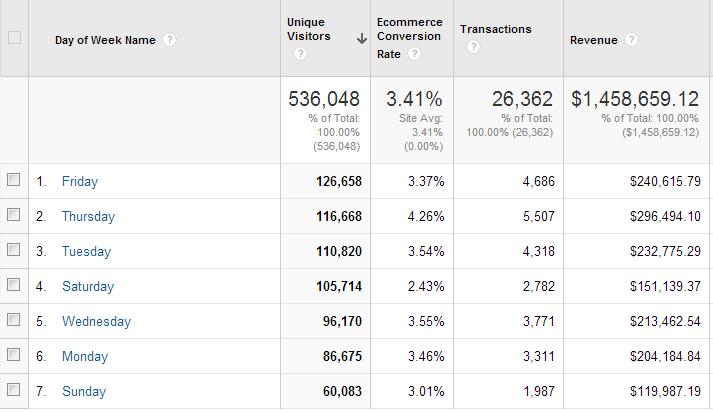
图表中的文字翻译如下:
| 星期 | 访问人数 | 商业转化率 | 交易 | 收入 | |
| 总数 | 百分比 | 总数 | 总数 | ||
| 周五 | |||||
| 周四 | |||||
| 周二 | |||||
| 周六 | |||||
| 周三 | |||||
| 周一 | |||||
| 周日 |
看见了吗?周四的收入是周六和周日收入的2倍多,周四的消费转化率几乎是周六的2倍。
如果我们没有按周为单位实施测试,结果就会不准确。以下为常规的测试循环:一次运行7天的测试。如果在这7天内没有出现差异显著的结果,则再运行7天。如果14天内还不显著,再运行7天。
当然,首先你需要运行测试至少2周(我个人是至少4周,因为2周通常是不准确的),然后再应用7天规则。
唯一可以打破这一规则的情况是,充分的历史数据显示,网站每天的转换率都是相同的。即使如此,最好也测试完整一周后再说。
始终关注外部因素
测试时间刚巧在圣诞节怎么办(译注:类比国内的双十一)?节假日胜出的版本可能跟一月份的优胜版本不同。如果某个版本在诸如圣诞节这样的购物季胜出,你肯定得在购物季结束后对它再进行测试。是否投放了大量的电视广告或者其他大型广告?这也会影响测试结果。你需要知道公司做了哪些(有可能影响测试结果的)营销推广活动。
外部因素肯定会影响测试结果。如果有疑问,那就再做测试。
UXRen
3. 没有流量(或转换数据),也进行A/B测试
如果你每月只能卖出一到两件商品,测试显示,B方案比A方案转换率高15%。可以得出这样的结论吗?不可以!
所有人都喜欢A/B测试,但在流量极小的情况下,它不应该作为转换率的优化工具。原因是,即使B方案好得多,也可能需要很长时间才能达到统计显著性。
所以,如果你花了5个月的时间进行测试,会白白浪费大量财力。相反,你应该进行大规模的彻底的改版——直接切换到B版本。不需要对比测试,只需切换——并关注银行账户的收入。这种做法,是大范围改进,比如50%或100%。而且应该能马上观察到对收入(或者潜在客户数量)的影响。时间就是金钱。不要浪费时间等待需要很长时间的测试结果。
UXRen
4. 测试不是基于假设
我喜欢吃意大利面。但是不太喜欢”意面测试“(把它扔到墙上,看它是否粘在墙上)。意大利面测试是指测试随意的想法,观察哪一个想法有效。这种随意的测试会付出巨大的代价,浪费宝贵的时间和流量。千万别这样做。测试之前需要有假设。什么是假设?
假设是基于有限证据提出的陈述,它可以被验证或证伪,并作为进一步研究的起点。
也不应是”意大利面假设“(随意陈述)。你需要完成适当的转化研究以发现问题出在哪里,通过分析以找出问题可能是什么,最终提出解决当前问题的假设。
如果在没有明确假设的情况下开展A/B测试,B相对A优化了15%,那很好,但是你从中了解到什么?什么都没有。增进对用户的了解才是我们更重要的工作。这有助于我们改进对用户的理解,提出更好的假设进行测试。
UXRen
5. 测试数据不发送到谷歌分析(Google Analytics)
平均值会撒谎,永远记住这一点。如果你得到了版本A比版本B优胜10%的结论,这还不是全部。你需要切分开各个测试指标再进行分析,这些细节里才洞察所在。
虽然许多测试工具都内置了指标分割的功能,但都无法与谷歌分析(Google Analytics)媲美。
你可以将测试数据发送到谷歌分析系统,并按你期望的方式进行细分。实际的情况是,人们会自定义维度或或事件。你可以进行高级细分,自定义报告。这些功能非常有用,并让你真正从A/B测试(包括失败的测试和未得出差异的测试)有所收获。
底线:每次都把你的测试数据发送到谷歌分析,并把那些无效数据从结果中剔除。
从这篇文章中可以了解谷歌分析的操作(https://conversionxl.com/blog/analyze-ab-test-results-google-analytics/)。
UXRen
6. 将宝贵的时间和流量浪费在愚蠢的测试上
你是在测试用户喜欢什么颜色吗?别。
没有最好的颜色,它只和视觉层级结构相关。当然,你可以在网上找到一些测试,有人通过测试颜色来获得收益,但这些都是显而易见的。不要浪费时间测试那些显而易见的选择,直接实现它就行了。你没有足够的流量,谁也没有。把你的流量用在高影响的指标上,测试那些数据驱动型假设。
UXRen
7. 第一次测试失败就放弃
你设计了一项测试,但没有提高转化率。那好吧,我们尝试在另一个页面运行测试?
不要这么快就放弃!大多数测试第一次都会失败。我知道你很不耐烦,我也和你一样,但迭代测试不可避免。你可以运行一项测试,从中有所收获,改进对用户的理解,优化假设。进行迭代测试,又有所收获,再优化假设。再运行迭代测试,如此反复。
我们曾经做过案例研究,其中包含了6次测试(测试同一页),以实现我们期望的提升。这才是真实的测试。那些批准测试预算的人—你的老板和客户—需要知道这一点。
如果期望一次测试就可以得出想要的结果,这样的想法会白白浪费金钱,导致很多人失去工作。其实不必一定是这个结果。测试的花费对每个人来说都是一大笔数字。运行迭代测试,才是资金的合理运用方式。
UXRen
8. 不懂虚报的显著性
统计显著性并不是唯一需要注意的因素。还需要理解错误的测试结果。没什么耐心的测试人员希望跳过A/B测试,直接进行A/B/C/D/E/F/G/H测试。这,就是我们要讨论的误区。
或者,为什么不继续再测呢?谷歌就曾经测试过41种蓝色阴影效果!
但这并非好主意。测试的版本越多,虚报显著性的几率就越高。同时测试41种蓝色阴影的实验设置下,即使置信度达到95%,错报概率也高达88%。
主要结论:不要一次测试太多的版本。不管怎样,最好做简单的A/B测试,会更快得到结果,并且会更快地了解用户,从而更多优化假设。
UXRen
9. 用重复的流量同时进行多个测试
你发现了一种同时运行多个测试的捷径:一个测试在产品页面,一个测试在购物车页面,还有一个在主页(同时测量相同的指标)。这样的设置很省时间,对吧?
但,如果设置不小心的话,这样可能会扭曲结果。除非你预估这多个测试之间有很强的交互性,且测试之间的流量有很大的重叠(即同一批人),这样做才是OK的。如果测试间存在交互性且流量重叠,情况也会比较复杂。
如果你想在同一任务流中同时测试多个布局样式的新版本,例如结帐的3个步骤,那么最好使用多页实验或MVT(Mass Verification Test,量产验证)来测量交互作用,并恰当地进行归因。
如果你决定使用重叠的流量运行A/B测试,请记住让流量均匀分布。流量应始终平均分配。如果测试产品页A和B,以及结算页C和D,则需要确保B页的流量是对半分进入C和D页,而不是其他。
UXRen
10. 忽略细微的成果
你提出的新版本对对照组胜出了4%。我曾听到有人说:“哎呀,这点成绩简直是小菜一碟!我都懒得费心去实施它。”
事实上,如果你的网站已经体验很好,流量不会一直有大幅的提升。实际上,流量大幅上升的情况是非常罕见的。如果现有网站很垃圾,每次测试后很容易发现提升幅度达到50%。但即使这样情况也不会是无止境的。
大多数测试中胜出的方案可能只有很小的提升—1%,5%,8%。有时,1%的提升也会带来数百万美元的收入。这完全取决于我们面对的绝对数值。但这里的关键是:你需要以12个月的时间跨度角度来看待这点提升。
当你只做了一次测试时,那就是一次测试。你要做很多很多的测试。如果你每个月都能把转化率提高5%,那么12个月内就会提升80%。这叫复利,通过数学计算出来。80%可不低。
所以,继续取得这些微小的收益吧。最后它们会形成累加效应。
UXRen
11. 没有一直运行测试
每一个没有测试的日子都是一种浪费。测试就是了解。了解你的用户,了解什么有效,以及为什么有效。你所有的洞察,都可以用于所有的营销活动,比如PPC广告(PayPerClick广告,点击付费广告)等等。
不测试,就不知道什么有效。测试需要时间和流量(而且需要很多流量)。
虽然要进行测试并一直运行,但这不意味着要做垃圾测试。绝对不要!你仍然要做适当的研究,提出恰当的假设等等。
测试要持续不断地运行。学习如何制定制胜的A/B测试计划。不断优化你的计划。
UXRen
12. 对效度威胁一无所知
即使具备了合适的样本量、适宜的置信水平和持续的监测,还无法保证你的测试结果有效。影响测试效度的因素有以下几个方面。
工具性误差
这是最常见的问题。当测试工具(或仪器)存在问题时,就会导致测试收集到的数据有缺陷。这通常是网站上的错误代码造成的,这将扭曲所有的测试结果。需要加倍小心这种误差。设置测试时,要像鹰眼一样盯紧。确认记录下了每个设定跟踪的目标和指标。如果某些指标没有发送数据(例如,“添加到购物车”的点击数据),马上停止测试,查找并解决问题,重置数据后再重新开始。
历史效应
外界的变化可能导致测试数据不准确。可能是你的企业或某位高管的丑闻,也可能是某个特殊的节假日(圣诞节、母亲节等),又或许是媒体的报道导致人们对你测试的某个方案有偏见。无论哪种情况,都要注意外界的变化。
选择偏差
当我们错误地假设某部分的流量代表整个流量时,就会发生这种情况。例如,你利用电子邮件列表将促销流量分发给正在测试的页面。较之于普通访客,订阅了电子邮件的用户会对该页面喜爱得多。于是,你根据忠实用户的反馈来优化页面(例如着陆页、产品页等),以为它们代表总体用户的情况。但事实往往并非如此!
错码效应
某个版本的代码有漏洞,导致测试数据出现缺陷。于是你提出了解决方案,让这个版本回归正常!然而,这个版本并没有胜出或带来差异。殊不知,你的解决方案在某些浏览器或设备上的显示并不佳。每当你提出新的解决方案,请确保运行质量一致性测试,以确保它们在所有浏览器和设备中正确显示。
UXRen
结论
时至今日,很多优秀的工具都可以让测试变得轻松容易,但是它们并不能替代你思考。我知道,统计学不是你大学时最喜欢的科目,但你应该好好温习温习了。从这12个误区中汲取教训,你就可以在测试中避开它们,取得真正的进步。
更多译文:
用户访谈的18个建议
做10年UX才能明白的9个道理
如何打造优秀的着陆页
这52个研究术语,你都听过么?
为人设计,请说人话
全部290+篇译文>>
申请加入UXRen翻译组>>

翻译:晓臣同学 审校:王猫猫
作者:Peep Laja
原文标题:《12 A/B Split Testing Mistakes I See Businesses Make All The Time》
原文链接:https://conversionxl.com/blog/12-ab-split-testing-mistakes-i-see-businesses-make-all-the-time/
发布日期:January 21, 2014
版权声明:
- 本文版权归:UXRen翻译组 所有;
- 微信公众号转载说明:
1)由于近期微信审理严格,若是该文章未在UXRen公众号上首发,请不要转载;
2)公众号转载时,请在文章底部贴上UXRen公众号二维码。 - 网站转载说明:
1)文章标题必须保留“UXRen译”字样;
2)转载文中必须保留:“UXRen翻译组”、“作者”、“译者”及“审校者”信息;
3)转载文末必须保留本译文网页链接地址; - 如未遵照上述规则转载,视为侵权,UXRen社区保留随时追责的权利。








{kind=link}