用户访谈获取的定性数据如何分析?

作者:梁芳@网易金融大数据实验室
原标题:非结构化数据分析与挖掘: 定性分析基础
非结构化数据中的一种,就是用户研究项目中获得的用户反馈信息。这类文本数据通常篇幅较大,单条数据记录中便包含着大量信息,其分析手段也以定性分析方法为主。本期将详细介绍相关的理论、一般过程,以及常用工具等,带大家更好地理解非结构化数据的价值与应用。
一、为什么要定性分析非结构化数据?
定性研究是用户研究常用的方法,它让我们得以掌握用户更深层的动机和需要。也因此,数据采集完成之后,我们会得到大量资料或文本信息。

概括来说,定性研究具备四大特性:
- 因研究个案数据有限,必须概括性地总结问题与结论;
- 为我们提供了多角度比较两个个案提供了可能;
- 在推断因果关系时可用的证据可能比较薄弱;
- 重视基于实地证据的结论总结与表达。

那么,与结构化数据常用的分析手段相比,定性资料该如何去分析?是否有方法可循?
二、定性资料的初步分析
与结构化数据分析最大的不同是,定性资料的分析在其收集过程中就已经开始了!
我们已经在资料收集上花费了大量时间,如果到了项目后期才开始分析这些资料,很可能带来两个后果:1,我们将无法再继续收集新的资料去填补资料间的断层。2,我们将无法再收集资料去验证分析过程发现的新假设。
通常,初步分析阶段可以作为的地方有很多,下面只是建议要做的6个方面。

下图为今年年初,网易金融大数据实验室进行的关于网易宝更名为网易支付的调研。该调研中,我们针对影响用户品牌接受度的各因素及其关系进行了梳理,并基于设计了(定性)测量方案。
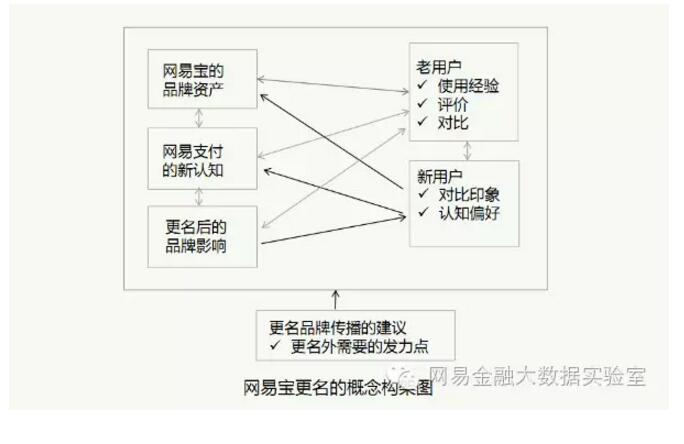

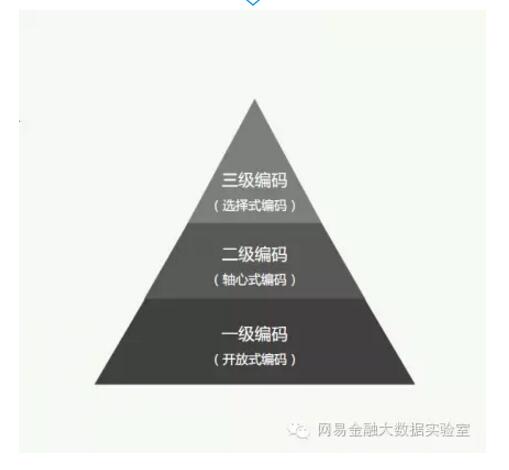
定性资料编码是一个严格的过程,学术界一般按照一、二、三级别编码的形式循序渐进。一级编码要求粒度尽可能细,能最直接地概括被编码内容;二级编码是对多个一级编码的概括与提炼,三级编码则是对二级编码的继续提炼。这种编码方法的目的是兼顾信息挖掘的全面性和条理性。
下图为网易理财PC端改版调研项目中使用的编码过程,通过编码之间的逐步“归纳”,我们逐渐找到了当前产品中的痛点,以及可以突破的发力点。
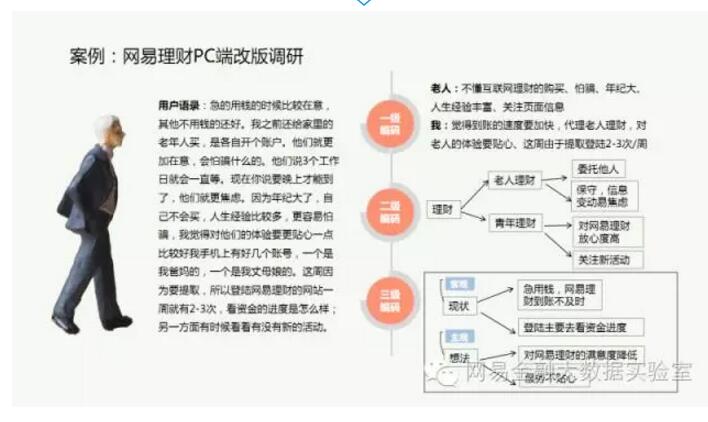
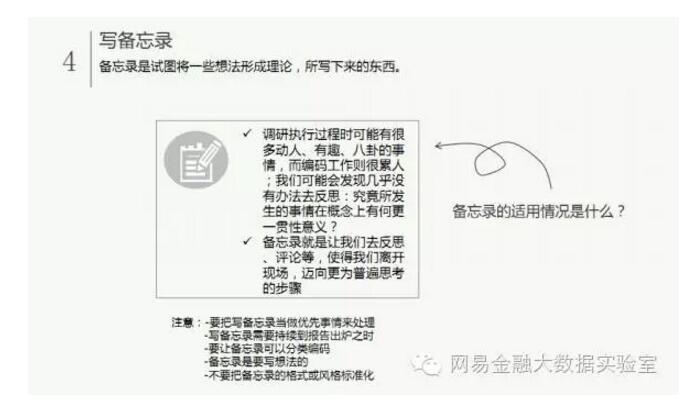


需要强调的是,一个项目中资料的分析并不是一次性的,需要我们根据项目的进展不断地补充新资料或回查原始资料。这一做法既能保证已有发现足够可信,也是为新发现寻找证据。当然,这也是为什么我们会说,资料的定性分析越早开始越好的原因!
三、标准化定性分析方法
下面主要讲述常用的定性资料分析方法,这些方法在我们过去写报告的时候或多或少都有使用过,可能只是不太知道具体方法的名字。
比如以证据建成一条逻辑链就要求我们将多渠道、多用户的反馈提炼出核心观点,这可能是跨研究方法的一种佐证。

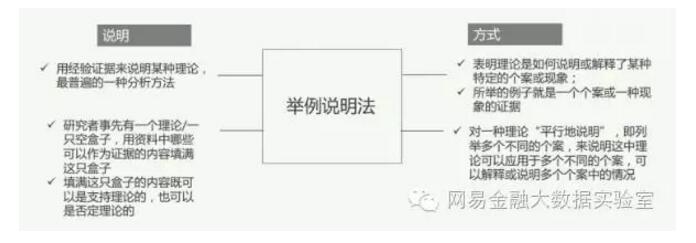
3.1 举例说明法
简单地说,举例说明法就是以典型案例的形式来表述一种结论,尤其是这个结论很抽象的时候。这种方法生动、易理解,对结论的表述又可以带有一定的原始信息,也更容易为需求方所接受。
当然,一个结论中,可能包含多个不同类型的“典型案例”。
3.2 清点法
可用性测试中,我们常以一个问题被反馈的次数去定义问题的严重性,这种方法轻松便捷,也足够说明问题。
但需要警惕的是,我们应该知道什么时候需要去处理频率问题,什么时候不需要去处理。在前公司曾有一个同事在做完调研的时候,下了一个结论:用户不关注PM2.5,不需要在产品中上线该功能,原因就是她访谈的5个用户均不关心。但这个结论是非常不恰当的,若再继续访谈几个人,可能结果就会完全不一样。

3.3 找出因素法
找出因素法,它要解决的问题是:我有一大堆资料在这儿,其中究竟有哪些是相关联的?
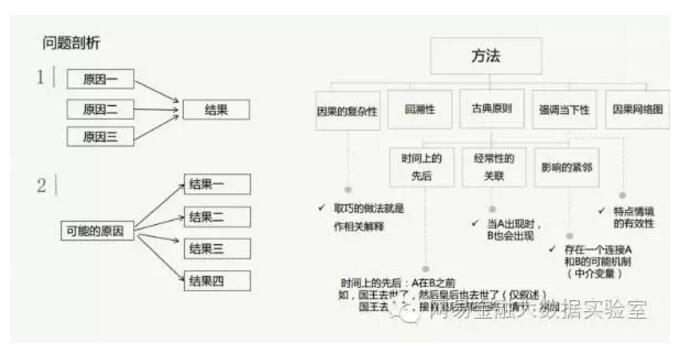
对于这种资料的处理,有两种声音:一种是认为定性研究不能解决因果关系问题,另一种认为可以找到一些方法去做解释。
找出因素法面临这一困境的原因是,因果关系是复杂的。一个问题,可能是一果多因,也可能是一因多果,还可能是存在中介变量。

应对这个问题取巧的方法就是做相关解释,而非因果分析。
另外也有一些原则可以帮助我们去找出因素,如强调当下性。例如Bartlett提出的问题:是什么因素使得一些小学生在教室排队的时候,是按性别排队?是老师安排?还是小学生的先前的社会化?还是偶尔群体的做法?或者是学校的“秩序”?
我们可以想到的原因有很多种,但如果说是有影响的话,其效果是此时此地的,因此这刻的关联就是什么老师、感觉了什么、说了什么、做了什么?其他学生感觉了什么、说了或做了什么。也就是说我们需要去强调的是“当下性”,而非与此相关的遥远的“素质”等因素。
3.4 其他方法
其实还有很多其他的方法帮助我们更好地分析定性资料,比如图表就是一种非常强的可视化方式。
另外,通过词云、语义网络等将一些关键信息形象突出地表现,能更好地达到分析的效果。
四、定性分析工具概览
上面说到的图表、词云、语义网络等方法,往往需要借助一定的分析工具。
随着定性研究技术的发展,成熟的工具也有很多,比如R脚本、Rost CM6、Nvivo、Atilas.ti 等均能满足基本的定性分析的需求。
但每个工具各有差异,使用的场景和目标也有所不同。
相对而言,Rost CM6分析成本最低,最快捷,但得到的结果是最粗糙,可靠性较低,一般在于资料的收集后的前期初步分析,去验证和发现初步想法。
其次是R脚本,R比较便捷的是有R包,我们可以从网上去下载它的分析语言,精确度高于Rost CM6,但时间成本稍微高一些。
最为专业的是Nvivo和Atilas.ti,能反复编码,深入分析,并能有效地展示资料。而它们的缺点就是需要进行人工编码和组织。我们可以根据自己的项目需要去灵活地选择分析工具。

实际项目中,我们选择哪款工具是根据当前要回答的问题决定的,每个工具也都有各自的优势。而这,也是我们在定性研究中使用使用工具的初衷!
文章转载来源:网易金融大数据实验室(公众号:wyjr_bigdata_lab)。